Classification
classification is a supervised learning approach in which the computer program learns from the data input given to it and then uses this learning to classify new observation.The goal is to predict discrete values, e.g. {1,0},{True,False},{spam,not spam}. I am going to work on titanic dataset where the goal is to predict if a person hanving a name,age,Pclass,Cabin is been survived or not.So the target is survived (O if no,1 if yes).I am going to treat our dataset with :
Logistic regression:
first,I import sklearn and necessary modules
import pandas as pd
import numpy as np
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestRegressor
import my_package.models.models as md
import my_package.preprocessing_data.preprocessing as prepro
import my_package.preprocessing_data.discovery as ds
I load titanic dataset
train = pd.read_csv("data/train.csv", sep=',')
train.head()

I clean my dataset from NAN value and replace undesired characters
def variable_manquante(model):
tab=[]
for ele in model.columns:
if True in list(model[ele].isnull().unique()):
tab.append(ele)
return tab
def remplace_mode_mediane(df,columnName) :
valeur=''
if df[columnName].dtype in ['float64','int64','float32','int32']:
x = df[columnName].median()
valeur=x
else :
x = df[columnName].mode()
valeur=x[0]
for index, row in df.iterrows() :
if pd.isna(row[columnName]) :
df.loc[index,columnName] = valeur
def replace_all_nan(model,tableau):
for ele in tableau:
remplace_mode_mediane(model,ele)
def replace_virg_point(model,column,typ):
model[column]=model[column].str.replace(',','.').astype(typ)
nan=ds.variable_manquante(train) # return a tableau des variables that contain NAN value
prepro.replace_all_nan(train,nan)
train.head()

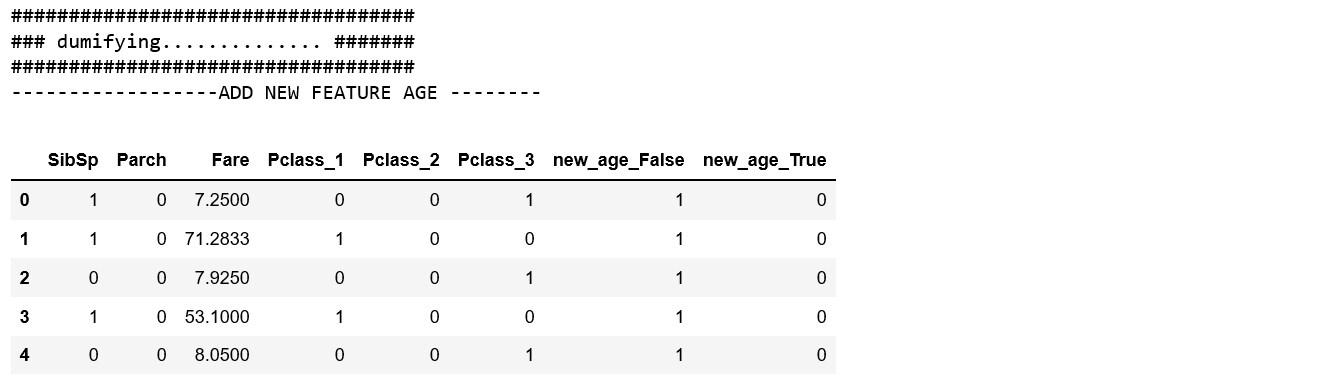
after cleaning process,dummifying is coming
def dumify(X,to_dummify):
return pd.get_dummies(X, columns=to_dummify)
print("###################################")
print("### dumifying.............. #######")
print("###################################")
print('------------------ADD NEW FEATURE AGE --------')
train['new_age']=train['Age']<10
feature_col=['SibSp', 'Parch', 'Fare','Pclass']
to_dummify=['Pclass']
to_predict=['Survived']
feature_col.append('new_age')
to_dummify.append('new_age')
y=train[to_predict]
X=train[feature_col]
X=dumify(X,to_dummify)
X.head()
Now our model is ready,we can compute score,accuracy.
def compute_score(clf, X, y):
xval = cross_val_score(clf, X, y, cv=10)
print("Accuracy: %0.2f (+/- %0.2f)" % (xval.mean(), xval.std() * 2))
def score(model,X_train,X_test,y_train,y_test):
clf = model.fit(X_train, y_train)
score = clf.score(X_test, y_test)
return score
def predire(model,X_test,y_test):
y_pred=model.predict(X_test)
return y_pred
print("###################################")
print("### Regression Logistic.... #######")
print("###################################")
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.05, random_state=0)
model=LogisticRegression()
score=md.score(model,X_train, X_test, y_train, y_test)
print("score == ",score)
md.compute_score(model, X, y)
y_pred=md.predire(model,X_test,y_test)
y_pred

finally,we get score of our model,we can try an other algorithm looking for a best score and accuracy.
Random Forest:
A random forest is a meta estimator that fits a number of decision tree classifiers on various sub-samples of the dataset and uses averaging to improve the predictive accuracy and control over-fitting
model_rf=RandomForestClassifier()
score_rf=md.score(model_rf,X_train, X_test, y_train, y_test)
print("score == ",score_rf)
md.compute_score(model_rf, X, y)
y_pred_rf=md.predire(model_rf,X_test,y_test)
print("y_predict===",y_pred_rf)
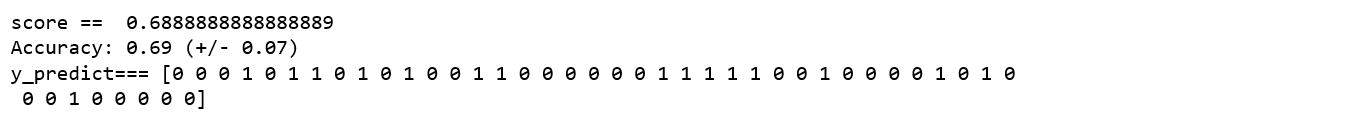
Grid Search Random Forest
Another way to choose which hyperparameters to adjust is by conducting an exhaustive grid search or randomized search
n_estimators = [int(x) for x in np.linspace(start = 200, stop = 1000, num = 10)]
max_features = ['auto', 'sqrt']
max_depth = [int(x) for x in np.linspace(100, 500, num = 11)]
max_depth.append(None)
# create random grid
random_grid = {
'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth
}
# Random search of parameters
rfc_random = RandomizedSearchCV(estimator = model_rf, param_distributions = random_grid, n_iter = 100, cv = 3, verbose=2, random_state=42, n_jobs = -1)
rfc_random.fit(X_train, y_train)
# print results
print(rfc_random.best_params_)
![]()
it give us the best parameters to estimate a best score
rfc_grid = RandomForestRegressor(n_estimators=644,max_features='auto',max_depth=180)
score_rf_grid=md.score(rfc_grid,X_train, X_test, y_train, y_test)
print("score ==",score_rf_grid)
md.compute_score(model_rf, X, y)

I hope you get new information about classification models………
- for more information about Regression
- thanks for supporting me on Twitter.